该数据结构实际上是从 SummarizedExperiment 继承而来。
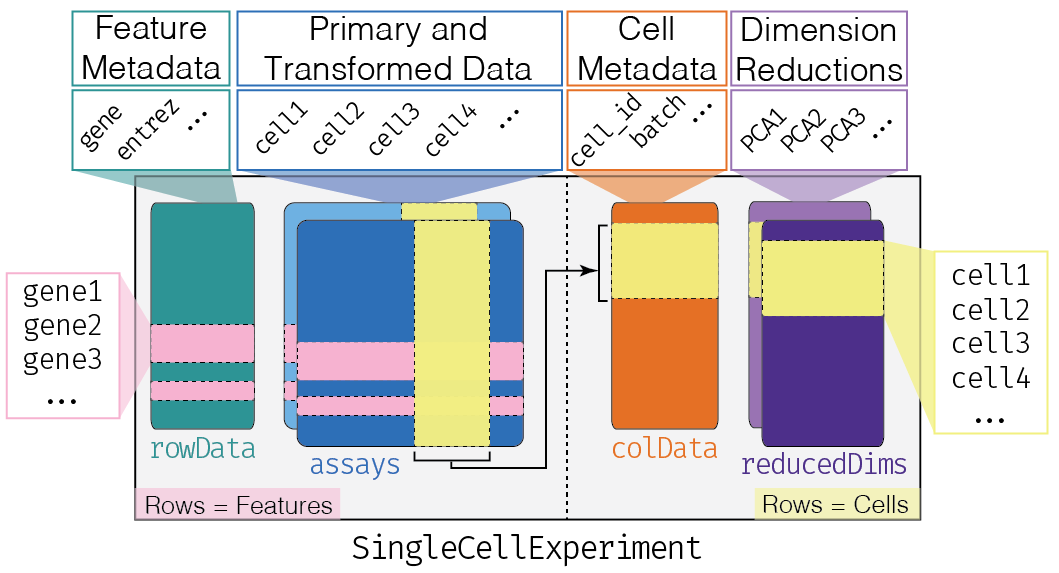
SingleCellExperiment 如 Figure 3.1 所示。
列数据(colData)
为了进一步构造对象SingleCellExperiment,需要添加列数据colData注释细胞或样本,该对象DataFrame中的行对应于细胞,列对应于样本数据字段,例如原产地批次batch of origin、处理条件treatment condition等( Figure 3.1 ,橙色框)。下载:E-MTAB-5522.sdrf.txt(第2页)
colData
Code
sdrf <- fread("data/SingleCellExperiment//E-MTAB-5522.sdrf.txt")
# 仅保留在计数矩阵的细胞 第44列=="counts_Calero_20160113.tsv"
coldata <- sdrf[sdrf$`Derived Array Data File` == "counts_Calero_20160113.tsv", ]
# 仅保留部分列和设置行标识符
coldata <- DataFrame(
genotype=coldata$`Characteristics[genotype]`,
phenotype=coldata$`Characteristics[phenotype]`,
spike_in=coldata$`Factor Value[spike-in addition]`,
row.names = coldata$`Source Name`
)
coldata
#> DataFrame with 96 rows and 3 columns
#> genotype
#> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> phenotype spike_in
#> <character> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> ... ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 wild type phenotype Premixed
添加之前确保colData的行名与计数矩阵的列名相同
Code
identical(rownames(coldata), colnames(counts))
#> [1] TRUE
添加colData
从头开始
Code
sce0 <- SingleCellExperiment(assays = list(counts=counts),
colData= coldata)
sce0
colData(sce0)
向现有对象添加
Code
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(0):
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(0):
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(1): sizeFactor
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
colData(sce) <- coldata
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(0):
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(0):
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(3): genotype phenotype spike_in
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
或者 分块添加
Code
sce1 <- SingleCellExperiment(list(counts=counts))
sce1$phenotype <- coldata$phenotype
colData(sce1)
#> DataFrame with 96 rows and 1 column
#> phenotype
#> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 wild type phenotype
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 wild type phenotype
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 wild type phenotype
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o..
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 wild type phenotype
函数自动添加
某些函数在colData中返回额外样本元数据字段,自动添加列元数据。
Code
sce <- scuttle::addPerCellQC(sce) #quality control metrics质量控制指标
colData(sce)
#> DataFrame with 96 rows and 6 columns
#> genotype
#> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> phenotype spike_in
#> <character> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> ... ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 wild type phenotype Premixed
#> sum detected total
#> <numeric> <numeric> <numeric>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 854171 7617 854171
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 1044243 7520 1044243
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 1152450 8305 1152450
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1193876 8142 1193876
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 1521472 7153 1521472
#> ... ... ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 203221 5608 203221
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 1059853 6948 1059853
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 1672343 6879 1672343
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 1939537 7213 1939537
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 1436899 8469 1436899
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(0):
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(0):
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(6): genotype phenotype ... detected total
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
行数据 ( rowData)
添加行数据rawData注释基因,DataFrame中每行对应一个基因,每列对应一个基因数据字段,例如转录本长度、基因符号等注释。( Figure 3.1 ,绿色框)
rowData
Code
rowData(sce)
#> DataFrame with 46603 rows and 0 columns
rowData(sce)$Length <- gene_length
rowData(sce)
#> DataFrame with 46603 rows and 1 column
#> Length
#> <integer>
#> ENSMUSG00000102693 1070
#> ENSMUSG00000064842 110
#> ENSMUSG00000051951 6094
#> ENSMUSG00000102851 480
#> ENSMUSG00000103377 2819
#> ... ...
#> ENSMUSG00000094431 100
#> ENSMUSG00000094621 121
#> ENSMUSG00000098647 99
#> ENSMUSG00000096730 3077
#> ENSMUSG00000095742 243
某些函数在rowData中返回额外基因元数据字段,自动添加行元数据。
Code
sce <- scuttle::addPerFeatureQC(sce)
rowData(sce)
#> DataFrame with 46603 rows and 3 columns
#> Length mean detected
#> <integer> <numeric> <numeric>
#> ENSMUSG00000102693 1070 0.0000000 0.00000
#> ENSMUSG00000064842 110 0.0000000 0.00000
#> ENSMUSG00000051951 6094 0.0000000 0.00000
#> ENSMUSG00000102851 480 0.0000000 0.00000
#> ENSMUSG00000103377 2819 0.0208333 1.04167
#> ... ... ... ...
#> ENSMUSG00000094431 100 0 0
#> ENSMUSG00000094621 121 0 0
#> ENSMUSG00000098647 99 0 0
#> ENSMUSG00000096730 3077 0 0
#> ENSMUSG00000095742 243 0 0
rowRanges
rowRanges:以GRangesList或 GRanges的形式保存基因组坐标,描述了特征(基因、基因组区域)的染色体、起始坐标和结束坐标。
Code
SummarizedExperiment::rowRanges(sce) #empty
#> GRangesList object of length 46603:
#> $ENSMUSG00000102693
#> GRanges object with 0 ranges and 0 metadata columns:
#> seqnames ranges strand
#> <Rle> <IRanges> <Rle>
#> -------
#> seqinfo: no sequences
#>
#> $ENSMUSG00000064842
#> GRanges object with 0 ranges and 0 metadata columns:
#> seqnames ranges strand
#> <Rle> <IRanges> <Rle>
#> -------
#> seqinfo: no sequences
#>
#> $ENSMUSG00000051951
#> GRanges object with 0 ranges and 0 metadata columns:
#> seqnames ranges strand
#> <Rle> <IRanges> <Rle>
#> -------
#> seqinfo: no sequences
#>
#> ...
#> <46600 more elements>
填充 rowRanges的方式取决于在比对和定量过程中使用的生物体种类和注释文件。 常用的是Ensembl 标识符,因此我们可以使用rtracklayer从包含 Ensembl 注释的 GTF 文件中载入GRanges。下载:Mus_musculus.GRCm38.82.gtf.gz
GTF(General Transfer Format)通用转录组注释格式
seqid 字符串 参考序列 ID(如染色体编号、 scaffold 编号),示例:chr1、NC_000001
source 字符串 注释来源(数据库或预测工具),示例:Ensembl、Gencode、augustus
type 字符串 注释特征类型(严格限定关键词),常见:gene、transcript、exon、CDS
start 整数 特征在参考序列上的起始坐标(1-based 索引,闭区间),示例:1001
end 整数 特征在参考序列上的终止坐标,示例:2000
score 浮点数 /. 置信度得分(预测工具输出),. 表示无数据,示例:95.3、.
strand 字符 链方向,+(正链)、-(负链)、.(未知)、?(不确定)
phase 整数 /. 仅 CDS 特征有效,0/1/2 表示密码子阅读框偏移,非 CDS 特征用.,示例:0、.
attributes 字符串 键值对属性(核心扩展字段),格式:key1 “value1”; key2 “value2”;
Code
gene_data <- rtracklayer::import("data/SingleCellExperiment/Mus_musculus.GRCm38.82.gtf.gz")
gene_data[1:6,1:9]
#> GRanges object with 6 ranges and 9 metadata columns:
#> seqnames ranges strand | source type score phase
#> <Rle> <IRanges> <Rle> | <factor> <factor> <numeric> <integer>
#> [1] 1 3073253-3074322 + | havana gene NA <NA>
#> [2] 1 3073253-3074322 + | havana transcript NA <NA>
#> [3] 1 3073253-3074322 + | havana exon NA <NA>
#> [4] 1 3102016-3102125 + | ensembl gene NA <NA>
#> [5] 1 3102016-3102125 + | ensembl transcript NA <NA>
#> [6] 1 3102016-3102125 + | ensembl exon NA <NA>
#> gene_id gene_version gene_name gene_source gene_biotype
#> <character> <character> <character> <character> <character>
#> [1] ENSMUSG00000102693 1 4933401J01Rik havana TEC
#> [2] ENSMUSG00000102693 1 4933401J01Rik havana TEC
#> [3] ENSMUSG00000102693 1 4933401J01Rik havana TEC
#> [4] ENSMUSG00000064842 1 Gm26206 ensembl snRNA
#> [5] ENSMUSG00000064842 1 Gm26206 ensembl snRNA
#> [6] ENSMUSG00000064842 1 Gm26206 ensembl snRNA
#> -------
#> seqinfo: 45 sequences from an unspecified genome; no seqlengths
# 整理数据
gene_data <- gene_data[gene_data$type=="gene",]
names(gene_data) <- gene_data$gene_id
# 保留gene_开头的列 metadata columns
library(GenomicRanges)
is.gene.related <- str_detect(colnames(mcols(gene_data)),"^gene_")
table(is.gene.related)
#> is.gene.related
#> FALSE TRUE
#> 21 5
mcols(gene_data) <- mcols(gene_data)[,is.gene.related]
mcols(gene_data) # 46603 × 5
#> DataFrame with 46603 rows and 5 columns
#> gene_id gene_version gene_name
#> <character> <character> <character>
#> ENSMUSG00000102693 ENSMUSG00000102693 1 4933401J01Rik
#> ENSMUSG00000064842 ENSMUSG00000064842 1 Gm26206
#> ENSMUSG00000051951 ENSMUSG00000051951 5 Xkr4
#> ENSMUSG00000102851 ENSMUSG00000102851 1 Gm18956
#> ENSMUSG00000103377 ENSMUSG00000103377 1 Gm37180
#> ... ... ... ...
#> ENSMUSG00000094431 ENSMUSG00000094431 1 CAAA01205117.1
#> ENSMUSG00000094621 ENSMUSG00000094621 1 CAAA01098150.1
#> ENSMUSG00000098647 ENSMUSG00000098647 1 CAAA01064564.1
#> ENSMUSG00000096730 ENSMUSG00000096730 6 Vmn2r122
#> ENSMUSG00000095742 ENSMUSG00000095742 1 CAAA01147332.1
#> gene_source gene_biotype
#> <character> <character>
#> ENSMUSG00000102693 havana TEC
#> ENSMUSG00000064842 ensembl snRNA
#> ENSMUSG00000051951 ensembl_havana protein_coding
#> ENSMUSG00000102851 havana processed_pseudogene
#> ENSMUSG00000103377 havana TEC
#> ... ... ...
#> ENSMUSG00000094431 ensembl miRNA
#> ENSMUSG00000094621 ensembl miRNA
#> ENSMUSG00000098647 ensembl miRNA
#> ENSMUSG00000096730 ensembl protein_coding
#> ENSMUSG00000095742 ensembl protein_coding
#rownames(sce) 46603行 观测基因
SummarizedExperiment::rowRanges(sce) <- gene_data[rownames(sce)]
SummarizedExperiment::rowRanges(sce)[1:6,]
#> GRanges object with 6 ranges and 5 metadata columns:
#> seqnames ranges strand | gene_id
#> <Rle> <IRanges> <Rle> | <character>
#> ENSMUSG00000102693 1 3073253-3074322 + | ENSMUSG00000102693
#> ENSMUSG00000064842 1 3102016-3102125 + | ENSMUSG00000064842
#> ENSMUSG00000051951 1 3205901-3671498 - | ENSMUSG00000051951
#> ENSMUSG00000102851 1 3252757-3253236 + | ENSMUSG00000102851
#> ENSMUSG00000103377 1 3365731-3368549 - | ENSMUSG00000103377
#> ENSMUSG00000104017 1 3375556-3377788 - | ENSMUSG00000104017
#> gene_version gene_name gene_source
#> <character> <character> <character>
#> ENSMUSG00000102693 1 4933401J01Rik havana
#> ENSMUSG00000064842 1 Gm26206 ensembl
#> ENSMUSG00000051951 5 Xkr4 ensembl_havana
#> ENSMUSG00000102851 1 Gm18956 havana
#> ENSMUSG00000103377 1 Gm37180 havana
#> ENSMUSG00000104017 1 Gm37363 havana
#> gene_biotype
#> <character>
#> ENSMUSG00000102693 TEC
#> ENSMUSG00000064842 snRNA
#> ENSMUSG00000051951 protein_coding
#> ENSMUSG00000102851 processed_pseudogene
#> ENSMUSG00000103377 TEC
#> ENSMUSG00000104017 TEC
#> -------
#> seqinfo: 45 sequences from an unspecified genome; no seqlengths
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(0):
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(5): gene_id gene_version gene_name gene_source
#> gene_biotype
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(6): genotype phenotype ... detected total
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
其他元数据
其他注释以命名列表存储在metadata 中。 例如,实验元数据,高度可变基因(highly variable genes)。。。,缺点是与表达矩阵的行或列的操作不同步。
Code
DEG_up <- c("gene_x", "gene_y")
metadata(sce) <- list(HVGs = DEG_up)
metadata(sce)
#> $HVGs
#> [1] "gene_x" "gene_y"
DEG_down <- c("gene_a", "gene_b")
metadata(sce)$DEG_down <- DEG_down
metadata(sce)
#> $HVGs
#> [1] "gene_x" "gene_y"
#>
#> $DEG_down
#> [1] "gene_a" "gene_b"
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(2): HVGs DEG_down
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(5): gene_id gene_version gene_name gene_source
#> gene_biotype
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(6): genotype phenotype ... detected total
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
子集和组合
子集
Code
first.10 <- sce[,1:10]
ncol(counts(first.10)) # 计数矩阵仅有 10 列
#> [1] 10
colData(first.10) # only 10 rows.
#> DataFrame with 10 rows and 6 columns
#> genotype
#> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S508.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N702_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N702_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> phenotype spike_in
#> <character> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S508.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S517.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N702_S502.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N702_S503.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> sum detected total
#> <numeric> <numeric> <numeric>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 854171 7617 854171
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 1044243 7520 1044243
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 1152450 8305 1152450
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1193876 8142 1193876
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 1521472 7153 1521472
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 866705 6828 866705
#> SLX-9555.N701_S508.C89V9ANXX.s_1.r_1 608581 6966 608581
#> SLX-9555.N701_S517.C89V9ANXX.s_1.r_1 1113526 8634 1113526
#> SLX-9555.N702_S502.C89V9ANXX.s_1.r_1 1308250 8364 1308250
#> SLX-9555.N702_S503.C89V9ANXX.s_1.r_1 778605 8665 778605
只想要野生型细胞
Code
wt.only <- sce[, sce$phenotype == "wild type phenotype"]
ncol(counts(wt.only))
#> [1] 48
colData(wt.only)
#> DataFrame with 48 rows and 6 columns
#> genotype phenotype
#> <character> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N701_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N702_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> ... ... ...
#> SLX-9555.N711_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N712_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N712_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N712_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl.. wild type phenotype
#> spike_in sum detected total
#> <character> <numeric> <numeric> <numeric>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 ERCC+SIRV 854171 7617 854171
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ERCC+SIRV 1044243 7520 1044243
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 ERCC+SIRV 1152450 8305 1152450
#> SLX-9555.N701_S517.C89V9ANXX.s_1.r_1 ERCC+SIRV 1113526 8634 1113526
#> SLX-9555.N702_S502.C89V9ANXX.s_1.r_1 ERCC+SIRV 1308250 8364 1308250
#> ... ... ... ... ...
#> SLX-9555.N711_S517.C89V9ANXX.s_1.r_1 Premixed 1317671 8581 1317671
#> SLX-9555.N712_S502.C89V9ANXX.s_1.r_1 Premixed 1736189 9687 1736189
#> SLX-9555.N712_S503.C89V9ANXX.s_1.r_1 Premixed 1521132 8983 1521132
#> SLX-9555.N712_S504.C89V9ANXX.s_1.r_1 Premixed 1759166 8480 1759166
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 Premixed 1436899 8469 1436899
只想保留蛋白质编码基因
Code
coding.only <- sce[rowData(sce)$gene_biotype == "protein_coding",]
nrow(counts(coding.only))
#> [1] 22013
rowData(coding.only)
#> DataFrame with 22013 rows and 5 columns
#> gene_id gene_version gene_name
#> <character> <character> <character>
#> ENSMUSG00000051951 ENSMUSG00000051951 5 Xkr4
#> ENSMUSG00000025900 ENSMUSG00000025900 9 Rp1
#> ENSMUSG00000025902 ENSMUSG00000025902 12 Sox17
#> ENSMUSG00000033845 ENSMUSG00000033845 12 Mrpl15
#> ENSMUSG00000025903 ENSMUSG00000025903 13 Lypla1
#> ... ... ... ...
#> ENSMUSG00000079808 ENSMUSG00000079808 3 AC168977.1
#> ENSMUSG00000095041 ENSMUSG00000095041 6 PISD
#> ENSMUSG00000063897 ENSMUSG00000063897 3 DHRSX
#> ENSMUSG00000096730 ENSMUSG00000096730 6 Vmn2r122
#> ENSMUSG00000095742 ENSMUSG00000095742 1 CAAA01147332.1
#> gene_source gene_biotype
#> <character> <character>
#> ENSMUSG00000051951 ensembl_havana protein_coding
#> ENSMUSG00000025900 ensembl_havana protein_coding
#> ENSMUSG00000025902 ensembl_havana protein_coding
#> ENSMUSG00000033845 ensembl_havana protein_coding
#> ENSMUSG00000025903 ensembl_havana protein_coding
#> ... ... ...
#> ENSMUSG00000079808 ensembl protein_coding
#> ENSMUSG00000095041 ensembl protein_coding
#> ENSMUSG00000063897 ensembl protein_coding
#> ENSMUSG00000096730 ensembl protein_coding
#> ENSMUSG00000095742 ensembl protein_coding
组合
按列组合,假设所有涉及的对象都具有相同的行注释值和兼容的列注释字段
Code
sce2 <- cbind(sce, sce)
ncol(counts(sce2)) # twice as many columns
#> [1] 192
colData(sce2) # twice as many rows
#> DataFrame with 192 rows and 6 columns
#> genotype
#> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 Doxycycline-inducibl..
#> phenotype spike_in
#> <character> <character>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 wild type phenotype ERCC+SIRV
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. ERCC+SIRV
#> ... ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 induced CBFB-MYH11 o.. Premixed
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 wild type phenotype Premixed
#> sum detected total
#> <numeric> <numeric> <numeric>
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 854171 7617 854171
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 1044243 7520 1044243
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 1152450 8305 1152450
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1193876 8142 1193876
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 1521472 7153 1521472
#> ... ... ... ...
#> SLX-9555.N712_S505.C89V9ANXX.s_1.r_1 203221 5608 203221
#> SLX-9555.N712_S506.C89V9ANXX.s_1.r_1 1059853 6948 1059853
#> SLX-9555.N712_S507.C89V9ANXX.s_1.r_1 1672343 6879 1672343
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1 1939537 7213 1939537
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1 1436899 8469 1436899
按行组合,假设所有对象都具有相同的列注释值和兼容的行注释字段。
Code
sce2 <- rbind(sce, sce)
nrow(counts(sce2)) # twice as many rows
#> [1] 93206
rowData(sce2) # twice as many rows
#> DataFrame with 93206 rows and 5 columns
#> gene_id gene_version gene_name
#> <character> <character> <character>
#> ENSMUSG00000102693 ENSMUSG00000102693 1 4933401J01Rik
#> ENSMUSG00000064842 ENSMUSG00000064842 1 Gm26206
#> ENSMUSG00000051951 ENSMUSG00000051951 5 Xkr4
#> ENSMUSG00000102851 ENSMUSG00000102851 1 Gm18956
#> ENSMUSG00000103377 ENSMUSG00000103377 1 Gm37180
#> ... ... ... ...
#> ENSMUSG00000094431 ENSMUSG00000094431 1 CAAA01205117.1
#> ENSMUSG00000094621 ENSMUSG00000094621 1 CAAA01098150.1
#> ENSMUSG00000098647 ENSMUSG00000098647 1 CAAA01064564.1
#> ENSMUSG00000096730 ENSMUSG00000096730 6 Vmn2r122
#> ENSMUSG00000095742 ENSMUSG00000095742 1 CAAA01147332.1
#> gene_source gene_biotype
#> <character> <character>
#> ENSMUSG00000102693 havana TEC
#> ENSMUSG00000064842 ensembl snRNA
#> ENSMUSG00000051951 ensembl_havana protein_coding
#> ENSMUSG00000102851 havana processed_pseudogene
#> ENSMUSG00000103377 havana TEC
#> ... ... ...
#> ENSMUSG00000094431 ensembl miRNA
#> ENSMUSG00000094621 ensembl miRNA
#> ENSMUSG00000098647 ensembl miRNA
#> ENSMUSG00000096730 ensembl protein_coding
#> ENSMUSG00000095742 ensembl protein_coding
单细胞特定字段
降维 reducedDims
降维结果保存在一个列表中,列表的每一个对象是一个代表计数矩阵的低维的数值矩阵,其中行表示计数矩阵的列(如细胞),列表示维度。
PCA
sce
#> class: SingleCellExperiment
#> dim: 46603 96
#> metadata(2): HVGs DEG_down
#> assays(1): counts
#> rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
#> ENSMUSG00000096730 ENSMUSG00000095742
#> rowData names(5): gene_id gene_version gene_name gene_source
#> gene_biotype
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(6): genotype phenotype ... detected total
#> reducedDimNames(0):
#> mainExpName: NULL
#> altExpNames(0):
sce <- scater::logNormCounts(sce)
sce <- scater::runPCA(sce)
head(reducedDim(sce, "PCA"))
#> PC1 PC2 PC3
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 25.3211829 -29.255059 19.924611
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 8.5853041 -24.268878 -18.126000
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 47.1785847 -10.430627 19.918057
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -0.7246197 42.677052 -18.786200
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -44.8772729 7.165398 -2.557318
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -38.3072406 7.030712 -6.703706
#> PC4 PC5 PC6 PC7
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 2.353028 0.7134296 -4.657165 -4.529785
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 9.457525 6.6261762 -7.374656 9.479859
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 9.043069 0.5371746 5.369461 -4.579162
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 10.052217 -11.2629834 5.066610 -3.989710
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 2.063798 23.2470805 9.972536 -2.224446
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 35.617030 11.8510185 -5.534609 -1.628105
#> PC8 PC9 PC10
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 12.739486 5.3528313 -17.4712747
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 9.933231 -3.0253703 -7.7697509
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -5.394808 -0.2653627 1.9569984
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1.609922 -5.9842292 4.2662705
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 0.922675 -3.3105931 -10.4905096
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -10.031722 1.3764729 -0.6400844
#> PC11 PC12 PC13
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 6.272022 1.309453 2.142689
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -8.628675 -23.782808 13.086537
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -1.742621 5.794494 1.081155
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 7.924183 4.118848 -1.318160
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -3.991925 2.945433 7.997875
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -2.048618 16.074028 -1.601696
#> PC14 PC15 PC16
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -3.21487530 -3.586042 -0.8868563
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -0.07695582 -1.622621 16.5055262
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 5.37813494 -4.204543 -2.4987753
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -3.08602026 -1.632896 14.2865809
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -2.60771987 19.278739 -10.3415881
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -14.46500274 -9.901801 14.8844890
#> PC17 PC18 PC19 PC20
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 8.3092835 -8.254021 3.2032199 8.400580
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -7.0968297 7.479420 2.3893440 11.335409
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 6.1373345 6.841587 2.0491731 -12.153631
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 10.6386401 -6.811841 4.3494316 11.066570
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -2.3761618 7.564805 -0.5513294 -2.781294
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -0.5659762 -2.644617 3.7978583 1.368715
#> PC21 PC22 PC23
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 6.046180 0.3084271 15.4402055
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -2.781302 10.9606893 0.9337166
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -7.230595 4.2540263 -3.7111678
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -4.998028 -3.7927570 -5.8715888
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -14.916002 -0.6490183 -5.7146241
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -16.096460 -1.5767236 1.6884199
#> PC24 PC25 PC26
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 4.681700 -6.8980048 -6.9414484
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -12.282928 -7.7927146 -15.5028217
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -2.971526 -1.0340304 3.0595966
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -7.261821 0.1469728 -0.3389878
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -6.742021 9.0437395 13.3845540
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 15.742625 2.8595182 1.0181258
#> PC27 PC28 PC29
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 2.542829 9.985183 -3.49240985
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 4.475004 -8.571937 1.37038588
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -7.788931 -3.190580 -0.07106325
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -4.334259 13.180193 -12.61790029
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -4.173710 5.856713 2.51899198
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 3.088050 -17.295198 -3.71292452
#> PC30 PC31 PC32
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -15.80727198 -0.5220196 7.013530
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 11.10310511 -6.5958587 13.719887
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -0.01329056 7.0592846 3.650680
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -1.88963759 18.5238767 2.819896
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -12.55439568 1.9920756 8.699811
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -11.41168626 4.4201476 5.879863
#> PC33 PC34 PC35 PC36
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -6.114895 -8.0054624 -8.761877 -8.7666596
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 11.659703 5.4103879 -5.109168 2.3577599
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 4.115808 2.7495522 2.431918 3.9233042
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -9.079732 -0.6305226 6.234937 -4.1432864
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 8.695278 -6.0949988 -4.720441 6.2858893
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -1.344748 -3.3667688 -5.063130 0.7113685
#> PC37 PC38 PC39 PC40
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -4.146180 -4.632087 -7.384395 5.3545001
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -8.559027 -1.528232 -6.537447 -0.6943536
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 2.049022 2.601003 -5.790073 0.4880258
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 8.396337 -5.866749 -4.707630 5.3081910
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -2.584457 -11.548363 -6.699724 -17.0674135
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 10.266019 4.807745 6.021079 1.2115131
#> PC41 PC42 PC43
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -3.939611 13.753571 -2.933861
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -8.165024 -8.682295 -5.419327
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -3.556190 -11.034037 1.609018
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1.450141 -3.135220 3.758943
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 7.091337 -9.855553 7.788290
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -1.975210 -1.080137 -14.012539
#> PC44 PC45 PC46
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 7.10867875 2.744699 0.3557068
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 0.09050595 3.099078 -3.0561133
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 0.63401271 -7.388260 -4.8308179
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 -4.57483871 6.691166 -4.6248279
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 9.95694101 -3.096031 4.8812097
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 1.94998482 0.468822 -6.8053076
#> PC47 PC48 PC49
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -2.91052787 -12.911035 0.9586156
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 0.99067457 3.865605 -9.6252109
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 0.05644908 7.466290 -14.3186667
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1.52787940 0.740261 -0.2277275
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 4.97965548 -6.475406 7.2102380
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -11.00798917 -2.598978 3.5586230
#> PC50
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 -1.468232
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 -4.673149
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -4.002830
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 1.546890
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 2.537450
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -7.319533
tSNE
sce <- scater::runTSNE(sce, perplexity = 0.1)
#> Perplexity should be lower than K!
head(reducedDim(sce, "TSNE"))
#> TSNE1 TSNE2
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 762.5866 -549.3040
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 336.7162 591.4587
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 -1167.2996 -411.6957
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 172.7646 -188.8121
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 575.0761 -1154.9966
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 139.4120 -1428.1949
UMAP
sce <- scater::runUMAP(sce)
head(reducedDim(sce,"UMAP"))
#> UMAP1 UMAP2
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 6.476384 0.92232811
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 5.694130 0.40770971
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 6.899131 1.31853854
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 8.024528 -0.69645191
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -8.901412 0.26416027
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -9.432525 0.08151817
手动添加UMAP
u <- uwot::umap(t(logcounts(sce)), n_neighbors = 2)
reducedDim(sce, "UMAP_uwot") <- u
reducedDims(sce) # Now stored in the object.
#> List of length 4
#> names(4): PCA TSNE UMAP UMAP_uwot
head(reducedDim(sce, "UMAP_uwot"))
#> [,1] [,2]
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1 4.899905 2.3621000
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 5.569812 0.4105074
#> SLX-9555.N701_S504.C89V9ANXX.s_1.r_1 4.316229 2.7554661
#> SLX-9555.N701_S505.C89V9ANXX.s_1.r_1 4.784112 4.8707987
#> SLX-9555.N701_S506.C89V9ANXX.s_1.r_1 -3.444970 0.4209308
#> SLX-9555.N701_S507.C89V9ANXX.s_1.r_1 -1.768182 1.6421386
Code
reducedDims(sce)
#> List of length 4
#> names(4): PCA TSNE UMAP UMAP_uwot
替代试验 Alternative Experiments
SingleCellExperiment提供了”替代实验”的概念,其是一组不同特征但同一组样本/细胞的数据。经典应用是存储加标转录(spike-in transcripts)的每细胞计数,能够保留这些数据以供下游使用,但要将其与保存的内源性基因计数分离,因为此类替代特征通常需要单独处理。
Code
df_spikein <- df_spikein |> tibble::column_to_rownames("GeneID")
spike_length <- df_spikein$Length
spike_mat<- as.matrix(df_spikein[,-1])
spike_mat[1:2,1:2]
#> SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> ERCC-00002 12948
#> ERCC-00003 220
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1
#> ERCC-00002 11287
#> ERCC-00003 911
首先创建一个单独的对象SummarizedExperiment
Code
spike_se <- SummarizedExperiment(list(counts=spike_mat))
spike_se
#> class: SummarizedExperiment
#> dim: 92 96
#> metadata(0):
#> assays(1): counts
#> rownames(92): ERCC-00002 ERCC-00003 ... ERCC-00170 ERCC-00171
#> rowData names(0):
#> colnames(96): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
#> SLX-9555.N712_S508.C89V9ANXX.s_1.r_1
#> SLX-9555.N712_S517.C89V9ANXX.s_1.r_1
#> colData names(0):
Code
altExp(sce, "spike") <- spike_se
altExps(sce)
#> List of length 1
#> names(1): spike
替代实验概念确保单细胞数据集的所有相关方面都可以保存在单个对象中,并且确保我们的加标数据与内源性基因的数据同步。
Code
sub <- sce[,1:2] # retain only two samples.
altExp(sub, "spike")
#> class: SummarizedExperiment
#> dim: 92 2
#> metadata(0):
#> assays(1): counts
#> rownames(92): ERCC-00002 ERCC-00003 ... ERCC-00170 ERCC-00171
#> rowData names(0):
#> colnames(2): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
#> SLX-9555.N701_S503.C89V9ANXX.s_1.r_1
#> colData names(0):
任何SummarizedExperiment对象都可以存储为alternative Experiment, 包括另一个 SingleCellExperiment。
缩放因子sizeFactors
Code
# 反卷积deconvolution-based size factors
sce <- scran::computeSumFactors(sce)
summary(sizeFactors(sce))
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.1513 0.7417 0.9478 1.0000 1.1239 3.5583
文库大小因子
Code
# library size-derived factors
sizeFactors(sce) <- scater::librarySizeFactors(sce)
summary(sizeFactors(sce))
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 0.1703 0.7657 0.9513 1.0000 1.1064 3.6050
聚类标签
该函数允许我们获取或设置每个细胞标签的向量或因子,通常对应于由无监督聚类分析的分组 或从分类算法预测细胞类型身份。
Code
colLabels(sce) <- scran::clusterCells(sce, use.dimred="PCA")
table(colLabels(sce))
#>
#> 1 2
#> 47 49