10 泛函purrr
高阶函数 (higher-order functions)
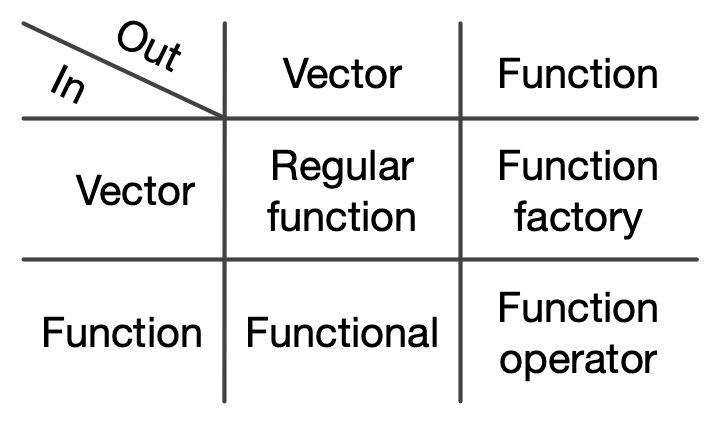
泛函(functionals)是将函数作为输入并返回向量作为输出的函数。
在R语言中,purrr是一个函数式编程包,它提供了一种简洁的方式来迭代数据结构。这个包的名字来源于它所提供的核心功能,即“纯”(pure)函数的迭代。在函数式编程中,纯函数是指给定相同的输入总是返回相同输出的函数,并且没有副作用(如更改全局变量的值->、写入磁盘write_csv()或显示在屏幕上print())。
10.1 map 变体
| 参数 \ 返回 | 列表 | 原子 | 同类型 | 无 |
|---|---|---|---|---|
| 一个参数 | map() |
map_lgl(), … |
modify() |
walk() |
| 两个参数 | map2() |
map2_lgl(), … |
modify2() |
walk2() |
| 一个参数 + 索引 | imap() |
imap_lgl(), … |
imodify() |
iwalk() |
| N 个参数 | pmap() |
pmap_lgl(), … |
— | pwalk() |
map 的基本构造如下,实际上是用 C 语言编写的,以节省性能,保留名称,并支持一些快捷方式。
10.1.1 返回列表
purrr::map(1:3,f) 接受一个向量和一个函数,为向量的每个元素调用一次函数,并在列表中返回结果,等价于list(f(1), f(2), f(3))
Show the code
triple <- function(x) x * 3
map(1:3, triple)
#> [[1]]
#> [1] 3
#>
#> [[2]]
#> [1] 6
#>
#> [[3]]
#> [1] 910.1.2 返回原子向量
map_lgl()、map_int()、map_dbl()、map_chr() 每个都返回一个指定类型的原子向量
Show the code
map_chr(mtcars, typeof)
#> mpg cyl disp hp drat wt qsec vs
#> "double" "double" "double" "double" "double" "double" "double" "double"
#> am gear carb
#> "double" "double" "double"
map_lgl(mtcars, is.double)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
n_unique <- function(x)length(unique(x))
map_int(mtcars, n_unique)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 25 3 27 22 22 29 30 2 2 3 6
map_dbl(mtcars, mean)
#> mpg cyl disp hp drat wt qsec
#> 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250 17.848750
#> vs am gear carb
#> 0.437500 0.406250 3.687500 2.812500
10.1.3 返回与输入类型相同的输出:modify()
Show the code
df <- data.frame(
x = 1:3,
y = 6:4
)
# 返回列表
map(df, ~ .x * 2)
#> $x
#> [1] 2 4 6
#>
#> $y
#> [1] 12 10 8
# 返回数据框
modify(df, ~ .x * 2)| x | y |
|---|---|
| 2 | 12 |
| 4 | 10 |
| 6 | 8 |
10.1.4 无返回
某些函数主要是为了它们的副作用(如cat()、write_csv()、ggsave())而被调用,并且捕获和存储它们的结果是没有意义的。
Show the code
walk(names, welcome)
#> Welcome Hadley!
#> Welcome Jenny!等价于write.csv(cyls[[1]]paths[[1]])、write.csv(cyls[[2]],paths[[2]])
write.csv(cyls[[3]], paths[[3]])
10.1.5 两个输入
Show the code
set.seed(10)
xs <- map(1:8, ~ runif(10))
# 权重
set.seed(100)
ws <- map(1:8, ~ rpois(10, 5) + 1)
xs[[1]][[1]] <- NA
xs
#> [[1]]
#> [1] NA 0.30676851 0.42690767 0.69310208 0.08513597 0.22543662
#> [7] 0.27453052 0.27230507 0.61582931 0.42967153
#>
#> [[2]]
#> [1] 0.65165567 0.56773775 0.11350898 0.59592531 0.35804998 0.42880942
#> [7] 0.05190332 0.26417767 0.39879073 0.83613414
#>
#> [[3]]
#> [1] 0.8647212 0.6153524 0.7751099 0.3555687 0.4058500 0.7066469 0.8382877
#> [8] 0.2395891 0.7707715 0.3558977
#>
#> [[4]]
#> [1] 0.53559704 0.09308813 0.16980304 0.89983245 0.42263761 0.74774647
#> [7] 0.82265258 0.95465365 0.68544451 0.50050323
#>
#> [[5]]
#> [1] 0.27548386 0.22890394 0.01443391 0.72896456 0.24988047 0.16118328
#> [7] 0.01704265 0.48610035 0.10290017 0.80154700
#>
#> [[6]]
#> [1] 0.3543281 0.9364325 0.2458664 0.4731415 0.1915609 0.5832220 0.4594732
#> [8] 0.4674340 0.3998326 0.5052856
#>
#> [[7]]
#> [1] 0.03188816 0.11446759 0.46893548 0.39698674 0.83361919 0.76112174
#> [7] 0.57335645 0.44750805 0.08380201 0.21913855
#>
#> [[8]]
#> [1] 0.07557029 0.53442678 0.64135658 0.52573932 0.03928139 0.54585984
#> [7] 0.37276310 0.96130241 0.25734157 0.20795168
# 未加权均值
map_dbl(xs, mean)
#> [1] NA 0.4266693 0.5927795 0.5831959 0.3066440 0.4616577 0.3930824
#> [8] 0.4161593
# 加权均值 weighted.mean()
map2_dbl(xs, ws, weighted.mean)
#> [1] NA 0.4590300 0.5834602 0.5998278 0.3067582 0.4448242 0.3947274
#> [8] 0.4418898
map2_dbl(xs, ws, weighted.mean, na.rm = TRUE)
#> [1] 0.3479728 0.4590300 0.5834602 0.5998278 0.3067582 0.4448242 0.3947274
#> [8] 0.441889810.1.6 遍历值和索引
imap(x, f)等价于map2(x, names(x), f)、map2(x, seq_along(x), f)
imap()通常可用于构建标签:
Show the code
imap_chr(iris, ~ paste0("The first value of ", .y, " is ", .x[[1]]))
#> Sepal.Length
#> "The first value of Sepal.Length is 5.1"
#> Sepal.Width
#> "The first value of Sepal.Width is 3.5"
#> Petal.Length
#> "The first value of Petal.Length is 1.4"
#> Petal.Width
#> "The first value of Petal.Width is 0.2"
#> Species
#> "The first value of Species is setosa"
map2_chr(iris,names(iris),~ paste0("The first value of ", .y, " is ", .x[[1]]))
#> Sepal.Length
#> "The first value of Sepal.Length is 5.1"
#> Sepal.Width
#> "The first value of Sepal.Width is 3.5"
#> Petal.Length
#> "The first value of Petal.Length is 1.4"
#> Petal.Width
#> "The first value of Petal.Width is 0.2"
#> Species
#> "The first value of Species is setosa"如果向量未命名,则第二个参数将是索引:
Show the code
x <- map(1:6, ~ sample(1000, 10))
imap_chr(x, ~ paste0("The maximum value of ", .y, " is ", max(.x)))
#> [1] "The maximum value of 1 is 965" "The maximum value of 2 is 978"
#> [3] "The maximum value of 3 is 949" "The maximum value of 4 is 871"
#> [5] "The maximum value of 5 is 843" "The maximum value of 6 is 848"
map2_chr(x,seq_along(x), ~ paste0("The highest value of ", .y, " is ", max(.x)))
#> [1] "The highest value of 1 is 965" "The highest value of 2 is 978"
#> [3] "The highest value of 3 is 949" "The highest value of 4 is 871"
#> [5] "The highest value of 5 is 843" "The highest value of 6 is 848"10.1.7 任意数量的输入
map2(x, y, f ) 等价于 pmap(list(x, y), f)
10.2 reduce 家族
通过迭代应用两个输入的函数(a binary function)将列表简化为单个值。
10.2.1 reduce()
reduce()获取长度为 n 的向量,并通过一次调用具有一对值的函数来生成长度为 1 的向量
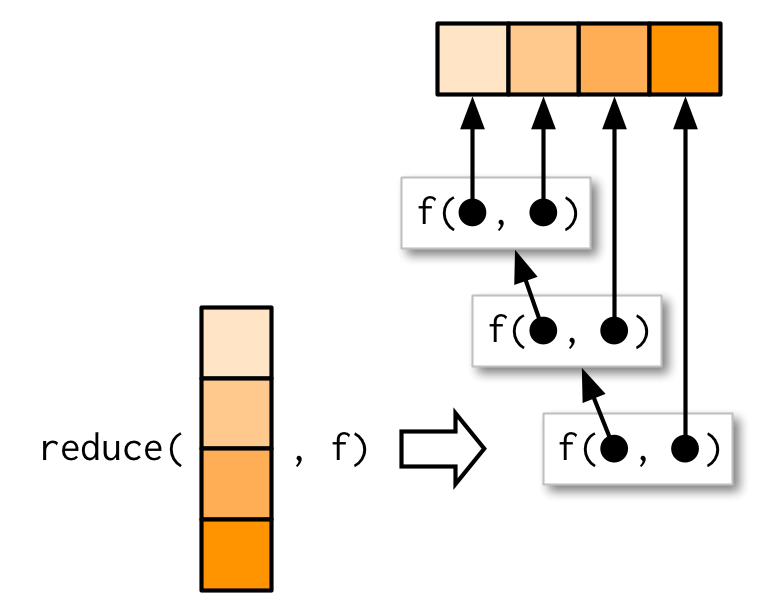
reduce(1:4, f)等价于f(f(f(1, 2), 3), 4)
10.2.2 accumulate()
第一个变体 ,不仅返回最终结果,还返回所有中间结果
Show the code
accumulate(l, intersect)
#> [[1]]
#> [1] 10 5 7 8 1 8 6 10 3 6 10 6 8 3 4
#>
#> [[2]]
#> [1] 10 5 7 1 4
#>
#> [[3]]
#> [1] 10 5 7 1 4
#>
#> [[4]]
#> [1] 10 5 7 4Show the code
x <- c(4, 3, 10)
reduce(x, `+`)
#> [1] 17
accumulate(x, `+`)
#> [1] 4 7 17
10.2.3 reduce2(x,y,f,.init)
10.3 谓词泛函
在编程和数学中,“谓词”(Predicate)是一个表达式,它返回一个布尔值(真或假)。谓词通常用于逻辑和函数式编程中,作为判断或决策的基础。
谓词泛函(Predicate Functionals)是谓词的一个特例,它是一个接受一个或多个参数,并返回一个布尔值的函数。谓词泛函在很多编程语言中都很常见,尤其是在支持函数式编程的语言中。
谓词泛函的一些关键特点包括:
返回布尔值:谓词泛函的输出是一个布尔值,即真(true)或假(false)。
接受参数:谓词泛函可以接收一个或多个参数,这些参数的值会影响函数的返回结果。
无副作用:在函数式编程中,谓词泛函通常是纯函数,即它们不会产生副作用,也不会修改外部状态。
逻辑判断:谓词泛函常用于逻辑判断,如条件语句(if)、循环(while、for)等。
-
some(.x, .p)如果存在元素匹配,则返回TRUE;every(.x, .p)如果所有元素都匹配,则返回TRUE;none(.x, .p)如果没有元素匹配,则返回TRUE当它看到第一个时返回,当它们看到第一个或时返回。
detect(.x, .p)返回第一个匹配项的值;detect_index(.x, .p)返回第一个匹配项的位置。keep(.x, .p)保留所有匹配的元素;discard(.x, .p)删除所有匹配的元素。
Show the code
df <- data.frame(
num1 = c(0, 10, 20),
num2 = c(5, 6, 7),
chr1 = c("a", "b", "c")
)
detect(df, is.factor)
#> NULL
detect_index(df, is.factor)
#> [1] 0
str(keep(df, is.factor))
#> 'data.frame': 3 obs. of 0 variables
str(discard(df, is.factor))
#> 'data.frame': 3 obs. of 3 variables:
#> $ num1: num 0 10 20
#> $ num2: num 5 6 7
#> $ chr1: chr "a" "b" "c"map变体也有谓词泛函
Show the code
str(map_if(df, is.numeric, mean))
#> List of 3
#> $ num1: num 10
#> $ num2: num 6
#> $ chr1: chr [1:3] "a" "b" "c"
str(modify_if(df, is.numeric, mean))
#> 'data.frame': 3 obs. of 3 variables:
#> $ num1: num 10 10 10
#> $ num2: num 6 6 6
#> $ chr1: chr "a" "b" "c"
str(map(keep(df, is.numeric), mean))
#> List of 2
#> $ num1: num 10
#> $ num2: num 610.4 base 包泛函
10.4.1 apply()
X,要汇总的矩阵或数组。MARGIN,一个整数向量,给出要汇总的维度, 1 = 行,2 = 列,以此类推(参数名称来自思考 联合分布的边距)。FUN,一个汇总函数。
Show the code
a3d <- array(1:24, c(4, 3, 2))
a3d
#> , , 1
#>
#> [,1] [,2] [,3]
#> [1,] 1 5 9
#> [2,] 2 6 10
#> [3,] 3 7 11
#> [4,] 4 8 12
#>
#> , , 2
#>
#> [,1] [,2] [,3]
#> [1,] 13 17 21
#> [2,] 14 18 22
#> [3,] 15 19 23
#> [4,] 16 20 24
apply(a3d, c(1, 2), mean)
#> [,1] [,2] [,3]
#> [1,] 7 11 15
#> [2,] 8 12 16
#> [3,] 9 13 17
#> [4,] 10 14 18lapply()、sapply() 和 vapply() 针对的都是列表结构的数据,sapply()是简化(simplified)版本的 lapply(),而 vapply() 则在 sapply() 的基础上加了结果验证,以保证可靠性。
Show the code
lapply(temp, basic)
#> [[1]]
#> min mean median max
#> 19.73327 31.09343 32.89923 39.89794
#>
#> [[2]]
#> min mean median max
#> 20.28530 23.00890 23.26734 24.30534
#>
#> [[3]]
#> min mean median max
#> 13.88828 23.72360 24.09008 32.81140
#>
#> [[4]]
#> min mean median max
#> 1.818265 31.437784 29.748184 58.731028
sapply(temp, basic)
#> [,1] [,2] [,3] [,4]
#> min 19.73327 20.28530 13.88828 1.818265
#> mean 31.09343 23.00890 23.72360 31.437784
#> median 32.89923 23.26734 24.09008 29.748184
#> max 39.89794 24.30534 32.81140 58.731028vapply() 第 3 个参数传入对每一个子集调用函数后结果的预期,上述设定为包含 4 个元素的数值型向量。
10.5 apply函数簇
10.5.1 apply()
Show the code
apply(X = mtcars, MARGIN = 2, FUN = mean)
#> mpg cyl disp hp drat wt qsec
#> 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250 17.848750
#> vs am gear carb
#> 0.437500 0.406250 3.687500 2.812500
10.5.2 aggregate()
| am | cyl | mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 22.90000 | 4 | 135.8667 | 84.66667 | 3.770000 | 2.935000 | 20.97000 | 1.000 | 0 | 3.666667 | 1.666667 |
| 1 | 4 | 28.07500 | 4 | 93.6125 | 81.87500 | 4.183750 | 2.042250 | 18.45000 | 0.875 | 1 | 4.250000 | 1.500000 |
| 0 | 6 | 19.12500 | 6 | 204.5500 | 115.25000 | 3.420000 | 3.388750 | 19.21500 | 1.000 | 0 | 3.500000 | 2.500000 |
| 1 | 6 | 20.56667 | 6 | 155.0000 | 131.66667 | 3.806667 | 2.755000 | 16.32667 | 0.000 | 1 | 4.333333 | 4.666667 |
| 0 | 8 | 15.05000 | 8 | 357.6167 | 194.16667 | 3.120833 | 4.104083 | 17.14250 | 0.000 | 0 | 3.000000 | 3.083333 |
| 1 | 8 | 15.40000 | 8 | 326.0000 | 299.50000 | 3.880000 | 3.370000 | 14.55000 | 0.000 | 1 | 5.000000 | 6.000000 |
Show the code
aggregate(.~am+cyl,
data = mtcars,
FUN = mean)| am | cyl | mpg | disp | hp | drat | wt | qsec | vs | gear | carb |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 22.90000 | 135.8667 | 84.66667 | 3.770000 | 2.935000 | 20.97000 | 1.000 | 3.666667 | 1.666667 |
| 1 | 4 | 28.07500 | 93.6125 | 81.87500 | 4.183750 | 2.042250 | 18.45000 | 0.875 | 4.250000 | 1.500000 |
| 0 | 6 | 19.12500 | 204.5500 | 115.25000 | 3.420000 | 3.388750 | 19.21500 | 1.000 | 3.500000 | 2.500000 |
| 1 | 6 | 20.56667 | 155.0000 | 131.66667 | 3.806667 | 2.755000 | 16.32667 | 0.000 | 4.333333 | 4.666667 |
| 0 | 8 | 15.05000 | 357.6167 | 194.16667 | 3.120833 | 4.104083 | 17.14250 | 0.000 | 3.000000 | 3.083333 |
| 1 | 8 | 15.40000 | 326.0000 | 299.50000 | 3.880000 | 3.370000 | 14.55000 | 0.000 | 5.000000 | 6.000000 |
Show the code
aggregate(mpg~am+cyl,
data = mtcars,
FUN = summary)| am | cyl | mpg |
|---|---|---|
| 0 | 4 | 21.50000 |
| 1 | 4 | 21.40000 |
| 0 | 6 | 17.80000 |
| 1 | 6 | 19.70000 |
| 0 | 8 | 10.40000 |
| 1 | 8 | 15.00000 |
10.5.3 by(), tapply()
by()是应用于数据框的tapply的面向对象包装器。
Show the code
by(data = mtcars[,1:3],
INDICES = list(cyl=mtcars$cyl),
FUN = summary)
#> cyl: 4
#> mpg cyl disp
#> Min. :21.40 Min. :4 Min. : 71.10
#> 1st Qu.:22.80 1st Qu.:4 1st Qu.: 78.85
#> Median :26.00 Median :4 Median :108.00
#> Mean :26.66 Mean :4 Mean :105.14
#> 3rd Qu.:30.40 3rd Qu.:4 3rd Qu.:120.65
#> Max. :33.90 Max. :4 Max. :146.70
#> ------------------------------------------------------------
#> cyl: 6
#> mpg cyl disp
#> Min. :17.80 Min. :6 Min. :145.0
#> 1st Qu.:18.65 1st Qu.:6 1st Qu.:160.0
#> Median :19.70 Median :6 Median :167.6
#> Mean :19.74 Mean :6 Mean :183.3
#> 3rd Qu.:21.00 3rd Qu.:6 3rd Qu.:196.3
#> Max. :21.40 Max. :6 Max. :258.0
#> ------------------------------------------------------------
#> cyl: 8
#> mpg cyl disp
#> Min. :10.40 Min. :8 Min. :275.8
#> 1st Qu.:14.40 1st Qu.:8 1st Qu.:301.8
#> Median :15.20 Median :8 Median :350.5
#> Mean :15.10 Mean :8 Mean :353.1
#> 3rd Qu.:16.25 3rd Qu.:8 3rd Qu.:390.0
#> Max. :19.20 Max. :8 Max. :472.0
by(data = mtcars[,1:3],
INDICES = factor(mtcars$cyl),
FUN = function(x) lm( disp ~ mpg, data = x))
#> factor(mtcars$cyl): 4
#>
#> Call:
#> lm(formula = disp ~ mpg, data = x)
#>
#> Coefficients:
#> (Intercept) mpg
#> 233.067 -4.798
#>
#> ------------------------------------------------------------
#> factor(mtcars$cyl): 6
#>
#> Call:
#> lm(formula = disp ~ mpg, data = x)
#>
#> Coefficients:
#> (Intercept) mpg
#> 125.122 2.947
#>
#> ------------------------------------------------------------
#> factor(mtcars$cyl): 8
#>
#> Call:
#> lm(formula = disp ~ mpg, data = x)
#>
#> Coefficients:
#> (Intercept) mpg
#> 560.87 -13.76
tapply(X = mtcars[,1:3],
INDEX = list(cyl=mtcars$cyl),
FUN = summary)
#> $`4`
#> mpg cyl disp
#> Min. :21.40 Min. :4 Min. : 71.10
#> 1st Qu.:22.80 1st Qu.:4 1st Qu.: 78.85
#> Median :26.00 Median :4 Median :108.00
#> Mean :26.66 Mean :4 Mean :105.14
#> 3rd Qu.:30.40 3rd Qu.:4 3rd Qu.:120.65
#> Max. :33.90 Max. :4 Max. :146.70
#>
#> $`6`
#> mpg cyl disp
#> Min. :17.80 Min. :6 Min. :145.0
#> 1st Qu.:18.65 1st Qu.:6 1st Qu.:160.0
#> Median :19.70 Median :6 Median :167.6
#> Mean :19.74 Mean :6 Mean :183.3
#> 3rd Qu.:21.00 3rd Qu.:6 3rd Qu.:196.3
#> Max. :21.40 Max. :6 Max. :258.0
#>
#> $`8`
#> mpg cyl disp
#> Min. :10.40 Min. :8 Min. :275.8
#> 1st Qu.:14.40 1st Qu.:8 1st Qu.:301.8
#> Median :15.20 Median :8 Median :350.5
#> Mean :15.10 Mean :8 Mean :353.1
#> 3rd Qu.:16.25 3rd Qu.:8 3rd Qu.:390.0
#> Max. :19.20 Max. :8 Max. :472.0
10.5.4 lapply(), sapply()
lapply() returns a list of the same length as X,
sapply() is a user-friendly version and wrapper of lapply() by default returning a vector or matrix
Show the code
x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,FALSE,TRUE))
lapply(X = x,FUN = quantile)
#> $a
#> 0% 25% 50% 75% 100%
#> 1.00 3.25 5.50 7.75 10.00
#>
#> $beta
#> 0% 25% 50% 75% 100%
#> 0.04978707 0.25160736 1.00000000 5.05366896 20.08553692
#>
#> $logic
#> 0% 25% 50% 75% 100%
#> 0.0 0.0 0.5 1.0 1.0
sapply(x, quantile)
#> a beta logic
#> 0% 1.00 0.04978707 0.0
#> 25% 3.25 0.25160736 0.0
#> 50% 5.50 1.00000000 0.5
#> 75% 7.75 5.05366896 1.0
#> 100% 10.00 20.08553692 1.0
10.5.5 vapply
Show the code
by_cyl <- split(mtcars, mtcars$cyl)
models <- lapply(by_cyl, function(data) lm(mpg ~ wt, data = data))
models
#> $`4`
#>
#> Call:
#> lm(formula = mpg ~ wt, data = data)
#>
#> Coefficients:
#> (Intercept) wt
#> 39.571 -5.647
#>
#>
#> $`6`
#>
#> Call:
#> lm(formula = mpg ~ wt, data = data)
#>
#> Coefficients:
#> (Intercept) wt
#> 28.41 -2.78
#>
#>
#> $`8`
#>
#> Call:
#> lm(formula = mpg ~ wt, data = data)
#>
#> Coefficients:
#> (Intercept) wt
#> 23.868 -2.192
vapply(models, function(x) coef(x)[[2]], double(1))
#> 4 6 8
#> -5.647025 -2.780106 -2.192438