# 数据结构 - 原子向量是基本数据类型(numeric,character,logical,complex 等)的数组(一维`vector` ,二维`matrix` ,多维`array` )。- 泛型向量是原子向量的集合,即列表`list` 。## 属性 - names,dimnames- length- dimensions(例如matrices,arrays)- class- 自定义属性- `class()` 函数,从面向对象编程的角度,知道其`class` 属性后就可以通过`methods()` 函数查找相应的泛型函数(generic function)对其操作。```{r} m1 <- matrix(1:6,nrow = 2) m1 class(m1) methods(class="matrix") ``` - `attributes()` 主要是用于列出对象所有已有的属性。```{r} attributes(m1) attr(x = m1,which = "dim") <- c(3,2) m1 # 或者 a <- structure( m1, dim=c(1,6) ) str(attributes(a)) a ``` 1. *"names"*,一个字符向量,为每个元素命名。```{r} # When creating it: x <- c(a = 1, b = 2, c = 3) x attributes(x) names(x) # By assigning a character vector to names() x <- 1:3 names(x) <- c("a", "b", "c") # Inline, with setNames(): x <- setNames(1:3, c("a", "b", "c")) ``` 2. *"dim"*,dimensions 的缩写,整数向量,用于将向量转换为矩阵或数组。```{r} z <- 1:6 dim(z) <- c(3, 2, 1) z class(z) attributes(z) dim(z) ``` ```{r} l <- list(1:5, "a", TRUE, 1.0) dim(l) <- c(2, 2) l class(l) attributes(l) l[[1,1]] ``` ## 原子向量 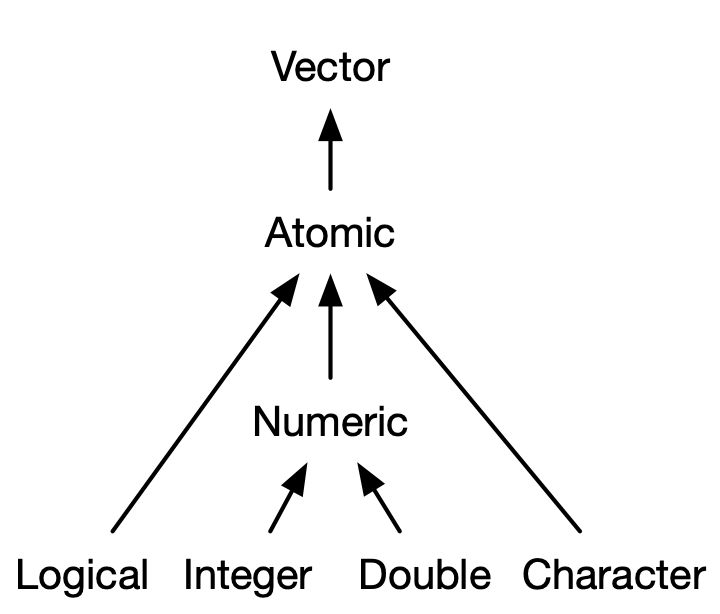 {fig-align="center" width="50%"}### vector ```{r} # 单元素向量 "a" == c ("a" )is.vector ("a" )# 函数c() Combine Values into a Vector or List c ("a" ,"b" ,"c" )c (list (1 ),list (T)) |> is.vector ()``` ### matricx ```{r} <- c (16 ,22 ,24 ,28 )<- c ("R1" ,"R2" )<- c ("C1" ,"C2" )<- matrix (num,nrow= 2 ,ncol= 2 ,byrow= TRUE ,dimnames= list (rnames,cnames))class (m)attributes (m)dim (m)rownames (m)colnames (m)``` #### 稀疏矩阵 Sparse matrix ```{r} library (Matrix)<- c (1 , 3 : 8 ) # 行指标 <- c (2 , 9 , 6 : 10 ) # 列指标 <- 7 * (1 : 7 ) # 数据 sparseMatrix (i, j, x = x)``` ```{r} = 100 = diag (1 , N, N)= sparseMatrix (1 : N, 1 : N, x = 1 )object.size (m)object.size (sp)``` ### array ```{r} <- 1 : 24 <- c ("A1" ,"A2" ,"A3" ) <- c ("B1" ,"B2" ,"B3" ,"B4" )<- c ("C1" ,"C2" ) <- array (v,c (3 ,4 ,2 ),dimnames = list (dim1,dim2,dim3)) class (array_3d)attributes (array_3d)dim (array_3d)dimnames (array_3d)``` ## S3类原子向量 1. 分类数据,其中值来自**factor**向量中记录的一组固定水平。2. 日期(具有日期分辨率),记录在**Date**向量中。3. 日期时间(具有秒或亚秒分辨率),存储在 **POSIXct** 向量中。4. 持续时间,存储在**difftime**向量中。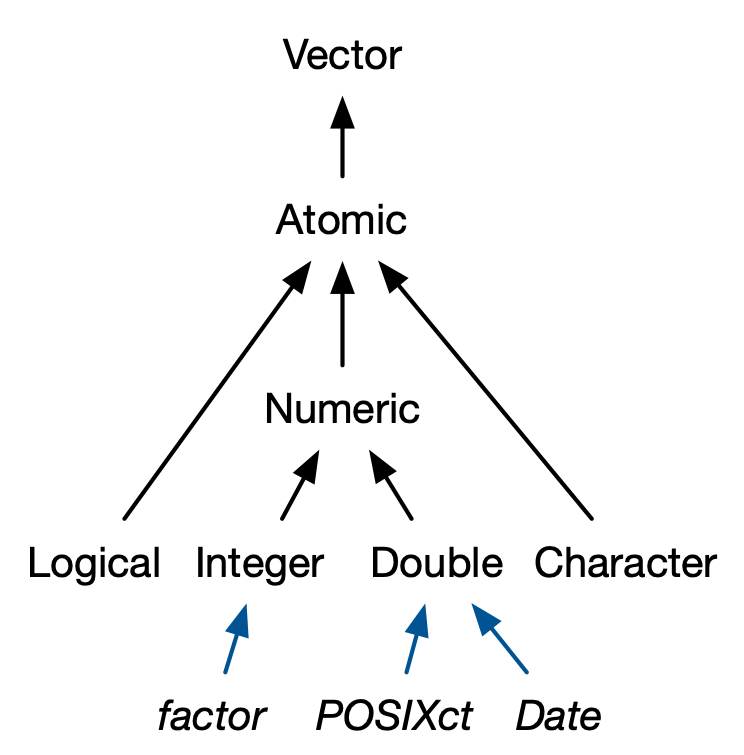 {fig-align="center" width="50%"}### factor `c(1,2,3,...,k)` 存储。```{r} # 存储形式 <- factor (c ("a" , "b" , "b" , "a" ))typeof (x)str (x)attributes (x)levels (x)class (x)# 名义变量 nominal variable <- c ("t1" ,"t2" ,"t1" ,"t1" ) attributes (diabetes)<- factor (diabetes)attributes (diabetes)# 顺序变量 ordinal variable 默认水平根据字母顺序而定 <- c ("poor" ,"better" ,"best" ,"poor" )<- factor (status,ordered = TRUE ) str (status) <- factor (status,ordered = TRUE ,levels = c ("poor" ,"better" ,"best" )) str (status) #改变外在标签 <- c (1 ,2 ,2 ,1 )<- factor (sex,levels= c (1 ,2 ),labels = c ("男" ,"女" )) str (sex) <- c (29 , 44 , 45 , 68 , 99 )# 连续型变量→因子 cut (breaks = c (0 , 18 , 45 , 65 , Inf ),labels = c ("minor" , "young" , "middle_age" , "elder" ),include.lowest = TRUE ,right = TRUE ``` ### Date `class "Date"` 属性。`"%Y-%m-%d" xxxx-xx-xx,例如:2023-03-15` ```{r} <- Sys.Date ()typeof (today)str (today)unclass (today)attributes (today)# 双精度值(通过删除class属性来查看)表示自 1970 年 1 月 1 日以来的天数 <- as.Date ("1970-02-01" )unclass (date)as.Date (c ("02 14-2002" ,"01 04-2013" ),"%m %d-%Y" ) #以"%m %d-%Y"格式读入 format (Sys.Date (),"%Y/%m/%d" ) #以"%Y/%m/%d"格式输出 ``` ### Datetime ```{r} <- as.POSIXct ("2024-04-20 15:45" , tz = "Asia/Shanghai" )typeof (dttm)str (dttm)attributes (dttm)unclass (dttm)``` ### Durations ```{r} <- as.difftime (1 , units = "weeks" ) #units = c("auto", "secs", "mins", "hours","days", "weeks")) typeof (units_1)attributes (units_1)unclass (units_1)units (units_1) <- "days" attributes (units_1)``` ## 泛型向量 ### list ```{r} <- list (1 ,2 ,3 )typeof (l1)``` 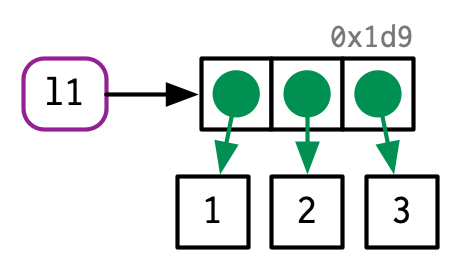 {#fig-list fig-align="center" width="50%"}`list(name1=object1,name2=object2,...)` ```{r} <- list (title = "My list" ,matr = matrix (c ("a1" , "b1" , "a2" , "b2" ),nrow = 2 ,ncol = 2 ,byrow = TRUE ,dimnames = list (c ("X1" , "X2" ), c ("Y1" , "Y2" ))df = data.frame (id = matrix (c ("Lisa" , "BOb" , "John" , "Jule" ),nrow = 4 ,ncol = 1 ,byrow = TRUE int = c (3 , 5 , 7 , 9 ),TF = c (T, T, T, F)list = list (a = c (1 , 2 , 3 ), b = c ("A" , "B" ))typeof (list1)attributes (list1)class (list1)names (list1)``` ### data frame/tibble `"list"` 之上的两个最重要的 S3 类是data.frame 和 tibble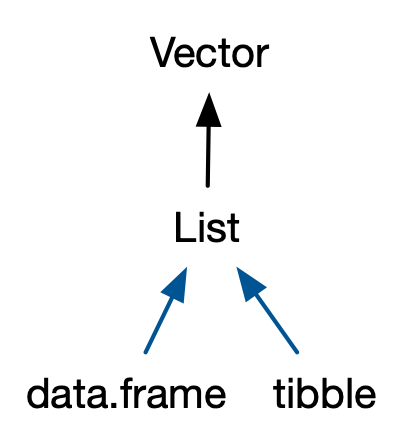 {fig-align="center" width="30%"}`names` ,`row.names` ,`class = "data.frame"` 属性的命名列表,是一种特殊的列表,每个原子向量的长度必须相同。```{r} <- c (001231 ,001241 ,001413 ,001244 ) <- c (21 ,14 ,52 ,15 ) <- c ("t1" ,"t2" ,"t1" ,"t1" ) <- c ("poor" ,"better" ,"best" ,"poor" ) <- data.frame (patientID= id,age,diabetes,status,row.names = c (1 ,2 ,3 ,4 ),stringsAsFactors = FALSE ) # 4个列向量组成数据框 typeof (df1)attributes (df1)colnames (df1)rownames (df1)``` ### tibble ```{r} library (tibble)tibble (x = c (1 , 2 , 5 ), y = c ("h" , "m" , "g" ),z = c (0.08 , 0.83 , 0.60 )tribble (~ x, ~ y, ~ z,1 , "h" , 0.08 ,2 , "m" , 0.83 ,5 , "g" , 0.60 ``` `tibblle` 与`data frame` 共享相同的结构。区别是`class` 属性更多,不会自动进行强制类型转换,不会自动转换非法名称(自动反引号非法名称), tibbles 只能循环较短的长度为 1 的向量,允许引用在构造过程中创建的变量。```{r error=TRUE} df2 <- tibble(x = 1:3, y = letters[1:3]) typeof(df2) attributes(df2) names(tibble(`1` = 1)) tibble(x = 1:4, y = 1) tibble(x = 1:4, y = 1:2) tibble( x = 1:3, y = x * 2 ) ``` #### 行名→列 ```{r} <- data.frame (age = c (35 , 27 , 18 ),hair = c ("blond" , "brown" , "black" ),row.names = c ("Bob" , "Susan" , "Sam" )|> rownames_to_column (var = "name" )as_tibble (df3, rownames = "name" )``` 


