Code
if(!require(psa)) remotes::install_github('jbryer/psa', dependencies = 'Enhances')Applied Propensity Score Analysis with R
https://ehsanx.github.io/EpiMethods/propensityscore.html
倾向性评分最大的优势是将多个混杂因素的多维影响用一维的倾向值(接受某处理的概率)来表示,即倾向性评分值(Propensity Score, PS),从而降低协变量的维度,因此该方法尤其适用于协变量较多的情况。
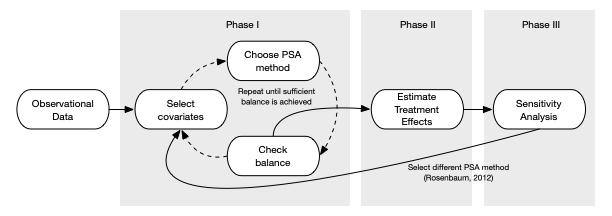
if(!require(psa)) remotes::install_github('jbryer/psa', dependencies = 'Enhances')倾向性评分的一般步骤为:
选择偏差模型
估计倾向分数:倾向得分是给定一组观察到的 covaraites 接受治疗的条件概率。 logistic 回归,分类树,随机森林
检查平衡 balance
重复前2步,直到优化足够的平衡
估计因果关系。
因果推断的基本难题:Y=ZY1 +(1-Z)Y0 , Z=0 或 1,2个实际结果,2个反事实结果
个体处理效应:
\[ ITE=\tau_i=y_i^1-y_i^0 \]
平均处理效应
\[ \widehat {ATE} =E(\tau)=E(Y^1-Y^0)=E(Y^1)-E(Y^0) \]
实验组平均处理效应ATT
对照组平均处理效应ATC
检查对未观察到的混杂因素的敏感性。
PS 值的估计是以处理因素作为因变量,其他混杂因素作为自变量,通过建立一个模型来估计每个研究对象接受处理因素的可能性。目前用于估计 PS 值的方法有 logistic 回归,Probit 回归、Bootstrapping、随机森林等。其中 logistic 回归是目前最常用的方法。
倾向性评分只是一个分数(P值),自己并没有均衡协变量(混杂因素)的能力,利用 PS 值均衡组间协变量分布的方法有匹配(matching)、分层(stratification)、协变量调整(covariate adjustment)和加权(weighting)等。其中协变量调整又可以称为倾向性评分回归、倾向性评分矫正等。
用于倾向性评分的数据要进行一些预处理,比如缺失值处理,比如直接删除,用常数值代替,用均值/中位数等代替,算法插补(KNN、随机森林等)
……
……
psa::psa_shiny()