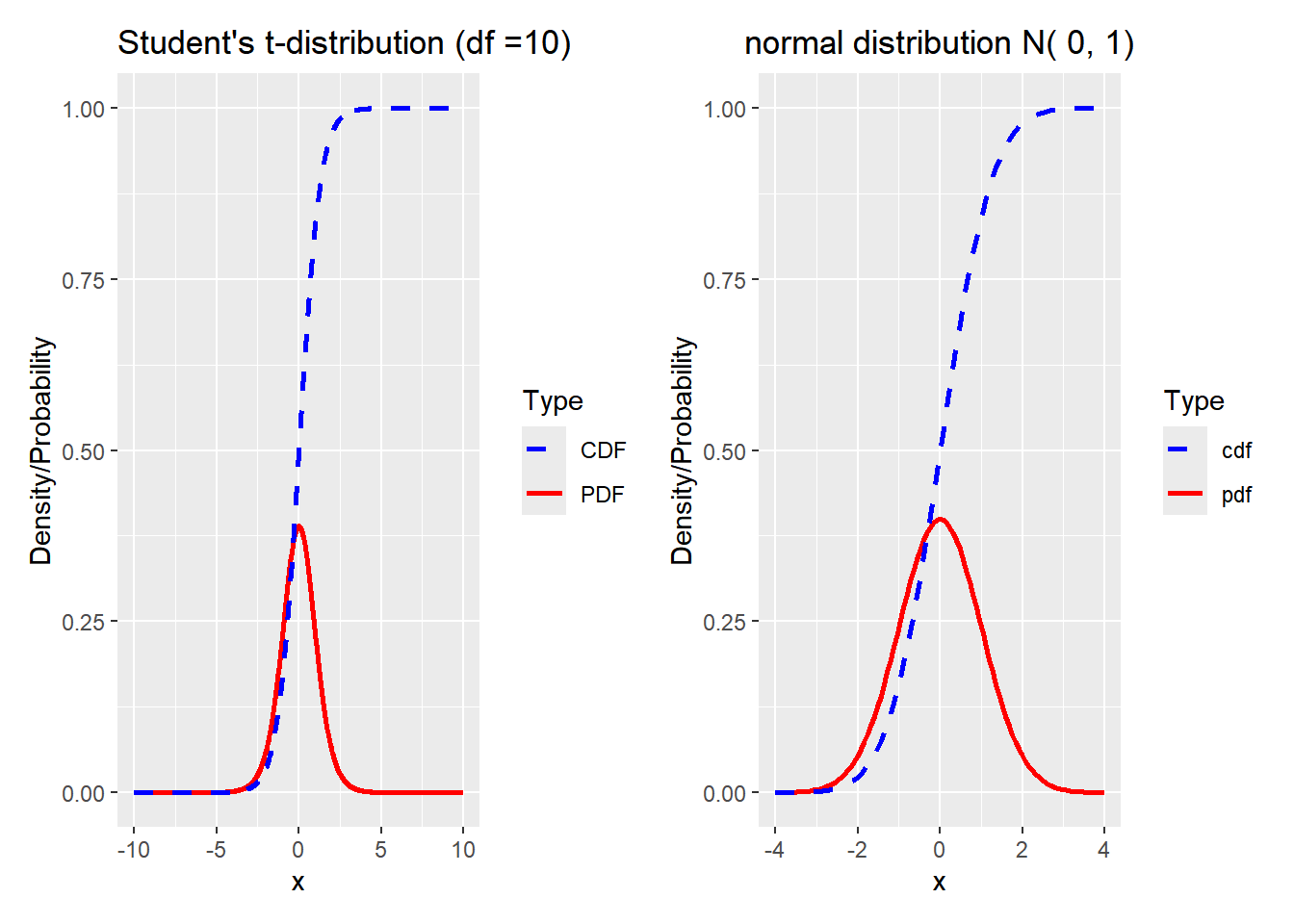
其中自由度(degrees of freedom)\(\nu=n-1\) 。当 \(\nu \to +\infty 时,t\sim N(0,1)\) 。
Code
t_distribution<-function(df=1, ...){# Generate sequence of x valuesx<-seq(-10, 10, length.out =1000)# Calculate the probability density function (PDF) and cumulative distribution function (CDF) valuespdf_values<-dt(x, df)cdf_values<-pt(x, df)# Create the ggplotggplot(data.frame(x, pdf_values, cdf_values), aes(x =x))+geom_line(aes(y =pdf_values, color ="PDF"), linewidth =1)+geom_line(aes(y =cdf_values, color ="CDF"), linewidth =1, linetype ="dashed")+scale_color_manual(values =c("PDF"="red", "CDF"="blue"))+scale_y_continuous(name ="Density/Probability")+scale_x_continuous(name ="x")+labs(title =paste("Student's t-distribution (df =", df, ")", sep =""))+guides(color =guide_legend(title ="Type"))}library(patchwork)t_distribution(df=10)|norm()
chisq_distribution<-function(df=1, ...){# Generate sequence of x valuesx<-seq(0, 20, length.out =1000)# Calculate the probability density function (PDF) and cumulative distribution function (CDF) valuespdf_values<-dchisq(x, df)cdf_values<-pchisq(x, df)# Create the ggplotggplot(data.frame(x, pdf_values, cdf_values), aes(x =x))+geom_line(aes(y =pdf_values, color ="PDF"), size =1)+geom_line(aes(y =cdf_values, color ="CDF"), size =1, linetype ="dashed")+scale_color_manual(values =c("PDF"="red", "CDF"="blue"))+scale_y_continuous(name ="Density/Probability")+scale_x_continuous(name ="x")+labs(title =paste("Chi square distribution (df =", df, ")", sep =""))+guides(color =guide_legend(title ="Type"))}(chisq_distribution(df=1)+chisq_distribution(df=2))/(chisq_distribution(df=4)+chisq_distribution(df=10))+plot_layout(guides ="collect")
F_distribution<-function(df1=1,df2=1, ...){# Generate sequence of x valuesx<-seq(0, 10, length.out =1000)# Calculate the probability density function (PDF) and cumulative distribution function (CDF) valuespdf_values<-df(x, df1,df2)cdf_values<-pchisq(x, df1,df2)# Create the ggplotggplot(data.frame(x, pdf_values, cdf_values), aes(x =x))+geom_line(aes(y =pdf_values, color ="PDF"), size =1)+geom_line(aes(y =cdf_values, color ="CDF"), size =1, linetype ="dashed")+scale_color_manual(values =c("PDF"="red", "CDF"="blue"))+scale_y_continuous(name ="Density/Probability")+scale_x_continuous(name ="x")+labs(title =paste("F distribution (df1 =", df1,", ","df2 = ",df2, ")", sep =""))+guides(color =guide_legend(title ="Type"))}(F_distribution(1,1)+F_distribution(3,1))/(F_distribution(3,15)+F_distribution(7,15))+plot_layout(guides ="collect")